 简体中文
简体中文


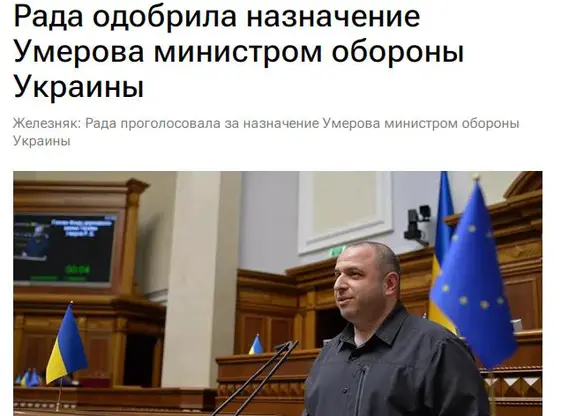
繼微軟、谷歌之後,臉書(Facebook)母公司Meta(Nasdaq:META)也加入AI軍備競賽。
當地時間2月24日,Meta官網公佈了一款新的人工智能大型語言模型LLaMA,從參數規模來看,Meta提供有70億、130億、330億和650億四種參數規模的LLaMA模型,並用20種語言進行訓練。
Meta首席執行官馬克·扎克伯格表示,LLaMA模型旨在幫助研究人員推進工作,在生成文本、對話、總結書面材料、證明數學定理或預測蛋白質結構等更復雜的任務方面有很大的前景。
怎麼理解人工智能大型語言模型的參數?
據悉,AIGC(利用人工智能技術來生成內容)形成的學習能力在一定程度上取決於參數的規模。Open AI推出的ChatGPT是通過其AI大模型GPT-3的基礎上通過指令微調後得到的,參數量達1750億,谷歌推出的Bard使用的是輕量級LaMDA模型,相比標準版本,輕量化版本模型所需要的運算能力較小,能面向更多使用者開放,使其參與體驗,有報道指出LaMDA模型參數量在1370億。百度文心大模型參數量達到2600億,阿里則表示,從過往實踐來看,其具備支撐超萬億參數大模型研發的技術實力。
Meta此次推出的大模型實力如何呢?
Meta首席AI科學家楊立昆(Yann LeCun)表示,在一些基準測試中,LLaMA 130億參數規模的模型性能優於OpenAI推出的GPT3,且能跑在單個GPU上;650億參數的LLaMA模型能夠和DeepMind 700億參數的Chinchilla模型、谷歌5400億參數的PaLM模型競爭。
法新社稱,按照Meta的表述,LLaMA是一套“更小、性能更好”的模型,且不同於谷歌的LaMDA和OpenAI的GPT機密訓練資料和演算,LLaMA是基於公開資料進行訓練。
Meta在官網表示,在大型語言模型中,像LLaMA這樣的小型基礎模型是可取的,因爲測試新方法、驗證他人的工作和探索新用例所需的計算能力和資源要少得多。基礎模型基於大量未標記的數據進行訓練,這使得它們非常適合於各種任務的微調。與其他大型語言模型一樣,LLaMA的工作原理是將一系列單詞作爲輸入,並預測下一個單詞以遞歸生成文本。
Meta稱將致力於這種開源模型的研究,新模型會開源給整個AI研究社區使用,並授予大學、非政府組織和行業實驗室訪問權限。另外,Meta表示其還有更多研究需要做,以解決大型語言模型中的偏見、有害評論等風險。
Meta披露的2022年第四季度財報顯示,該公司已連續第三個季度出現營收同比下滑,四季度營收312.54億美元,同比下降4%。廣告爲Meta的支柱業務,爲第四季度的總營收貢獻超97%,報告期內,儘管廣告展現量增長了23%,但單位廣告價格下滑了22%。
截至美東時間2月24日,Meta股價跌0.96%報170.390美元/股,總市值4418億美元。
(來源:中新網)